Distilling SDXL to infer in fewer steps 🔗
In 2022, a team of researchers from NVIDIA and the University of Chicago defined the Generative Learning Trilemma1, a trade-off space between three desirable properties of image generative models: speed (fast sampling), quality (high-quality samples) and diversity (mode coverage).
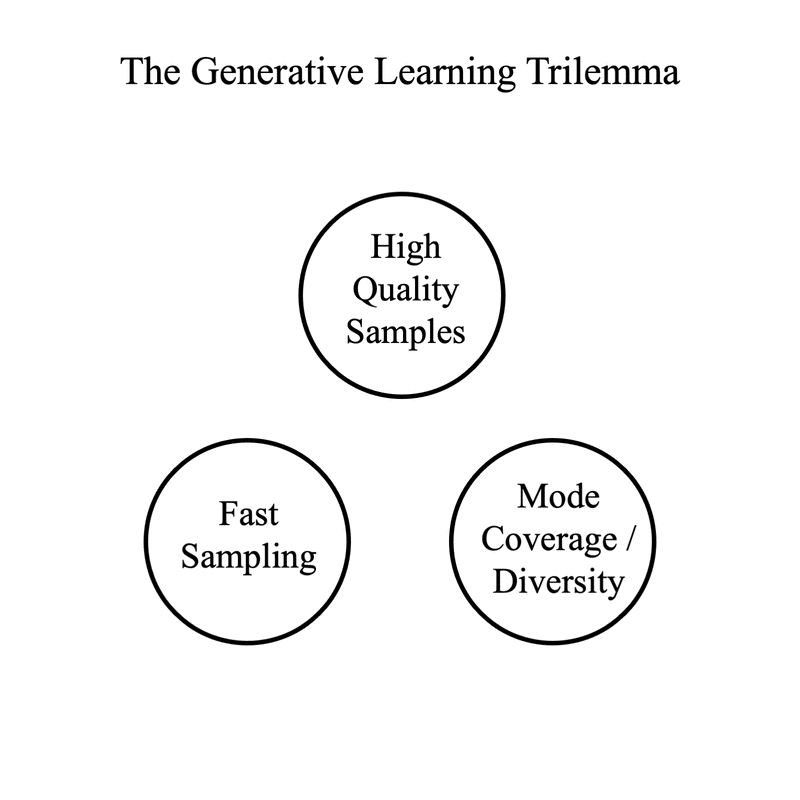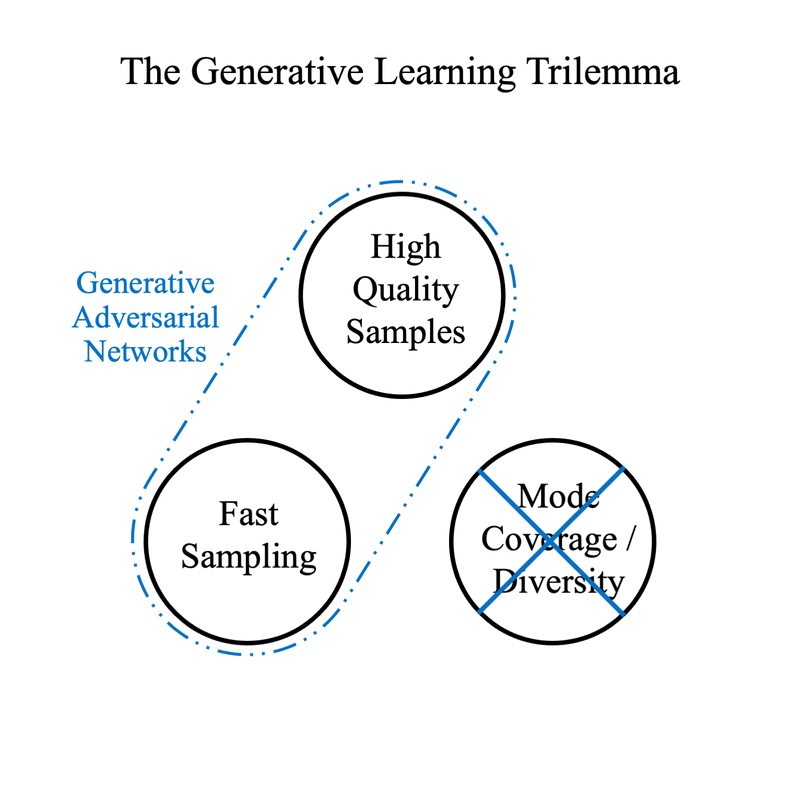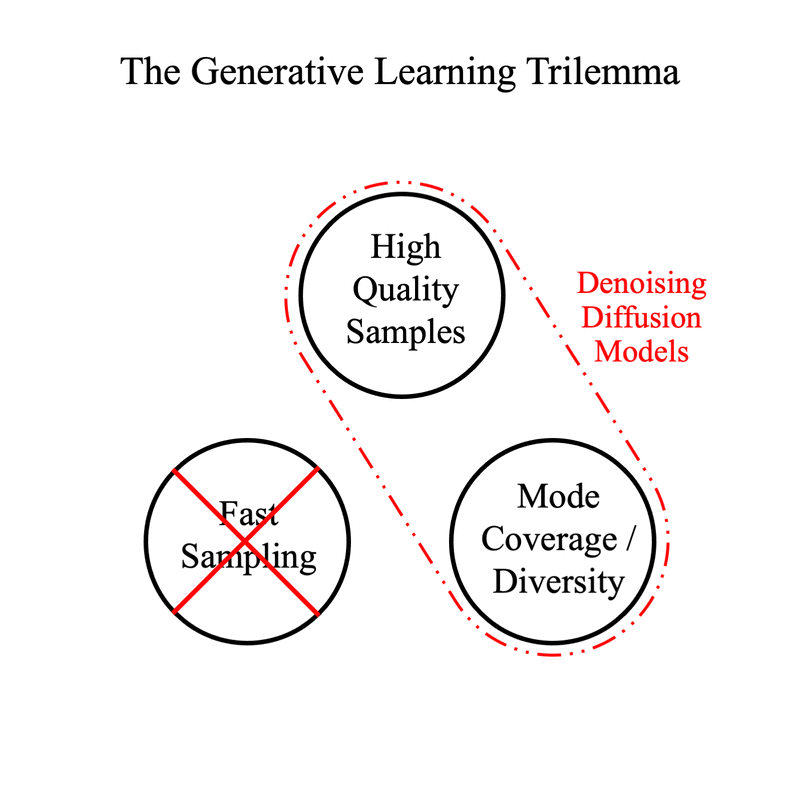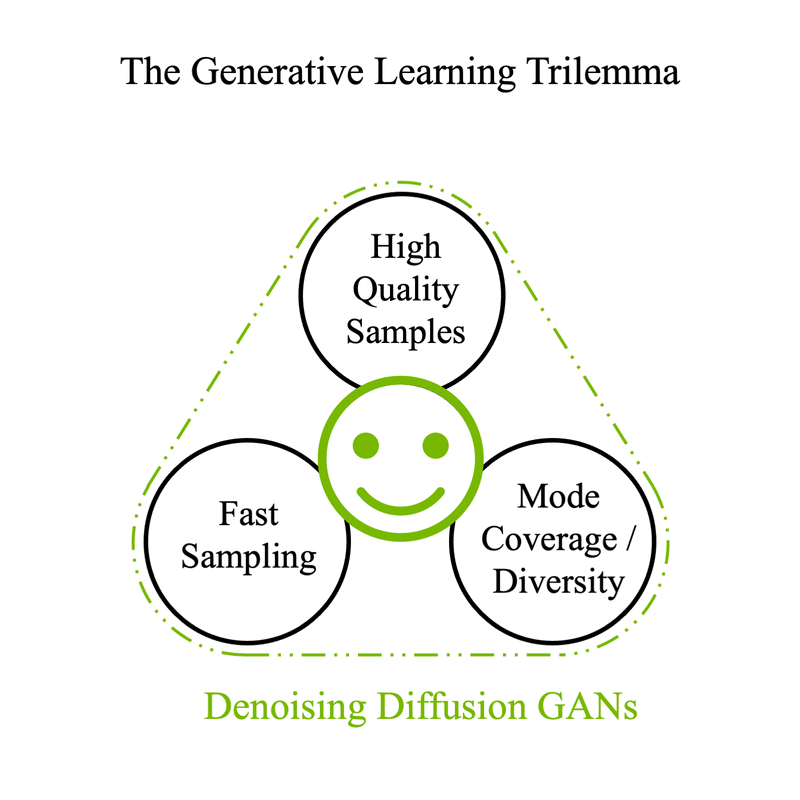
Denoising Diffusion models, including Latent Diffusion models such as Stable Diffusion, typically eschew speed in favor of the other two. They can be distilled into models which achieve faster results by using fewer inference steps while retaining as much quality and diversity as possible. Refiners 0.4 ships with support for two instances of such models for Stable Diffusion XL: Latent Consistency Models and SDXL Lightning.
A latent diffusion process starts from image latents and gradually adds noise to them until they are indistinguishable from pure noise2. Inference is the reverse process: a model is trained to predict the noise added at a given step. Another way to see it is to consider the generation process as a flow described by a differential equation, and the predicted noise as a gradient of that flow.
To reduce the number of steps, we use solvers such as DDIM3 or DPM++4 that estimate the effect of several diffusion steps based on that gradient. This lets us generate images with acceptable quality using 15 to 50 steps. To go lower, we must turn to model distillation.
LCM and LCM-LoRA 🔗
The first distillation approach we added is LCM5. I won’t get into the details of how consistency models6 work, but the important thing to understand is that they approximate the denoised latents in a single step. However, it is possible to improve the result by reinjecting noise corresponding to a given timestep and denoising again.
LCM is implemented as a custom solver which approximates DPM++. It does not support the usual classifier-free guidance from SDXL, but it does support a condition scale that is passed through an embedding that we inject using an adapter in Refiners.
After releasing LCM, the team behind it collaborated with Hugging Face to release LCM-LoRA7. They showed that it was possible to convert LCM into a LoRA for the UNet, which worked with any SDXL base model. To do that, they had to freeze the guidance scale embedding value (they picked 8.0), however when using the LoRA you get back the ability to use SDXL CFG, although you should pick small values for it.
SDXL Lightning 🔗
LCM is already great, but last week a team at ByteDance released an even more impressive distilled model: SDXL Lightning8. Their approach combines the best of adversarial distillation — using the encoder part of the UNet as a discriminator — with progressive distillation. This means the model can predict several denoising steps at once, but not necessarily the denoised latents. When used with several steps, this makes it more compatible with existing adapters for SDXL such as LoRAs and ControlNets. Its results are also better than LCM.
Building on the results from LCM-LoRA, the team behind SDXL Lightning went one step further and distilled the model as LoRAs directly, then merged those LoRAs with the full weights of SDXL and fine-tuned them to obtain full snapshots of slightly higher quality. In Refiners, you can use either.
An impressive fact about SDXL Lightning is that it uses exactly the same model architecture as SDXL and does not require a specific solver: it can be used with the standard Euler solver with well-chosen settings.
The approach does have a few drawbacks though. First, like LCM-LoRA, it hardcodes the CFG guidance scale into the refined weights (they picked 6.0). Second, the model snapshot is different depending on the number of steps you want to use for inference.
Results 🔗
Finally, let us look at how this all looks. Here is from left to right: base SDXL with DDIM, LCM, LCM-LoRA, SDXL Lightning as a full model, and SDXL Lightning as a LoRA. All distilled models were used with 4 steps while base SDXL used 30.

Both LCM and SDXL Lightning, using LoRA or not, are available now in Refiners 0.4. Try them out!
Pierre from the Finegrain Team
Xiao, Z., Kreis, K. and Vahdat, A., 2021. Tackling the generative learning trilemma with denoising diffusion gans. ↩︎
Song, J., Meng, C. and Ermon, S., 2020. Denoising diffusion implicit models. ↩︎
Lu, C., Zhou, Y., Bao, F., Chen, J., Li, C. and Zhu, J., 2022. Dpm-solver++: Fast solver for guided sampling of diffusion probabilistic models. ↩︎
Luo, S., Tan, Y., Huang, L., Li, J. and Zhao, H., 2023. Latent consistency models: Synthesizing high-resolution images with few-step inference. ↩︎
Song, Y., Dhariwal, P., Chen, M. and Sutskever, I., 2023. Consistency models. ↩︎
Luo, S., Tan, Y., Patil, S., Gu, D., von Platen, P., Passos, A., Huang, L., Li, J. and Zhao, H., 2023. Lcm-lora: A universal stable-diffusion acceleration module. ↩︎
Lin, S., Wang, A. and Yang, X., 2024. SDXL-Lightning: Progressive Adversarial Diffusion Distillation. ↩︎