Introduction 🔗
Style Aligned is a novel “optimization-free” method for Stable Diffusion based models, published by Google Research in December 2023, designed to enforce style consistency across generated images of the same batch.
Essentially it turns the following generated images:

Into:

We clearly see that the style of the generated images has been aligned to the style of the first image of the batch (aka reference image). The above images were made using a the notebook provided by Google Research in their github repository (slightly modified to also generate an unaligned version of the images, at set seed for comparison purposes).
Combined with a latent inversion technique and a captioning tool (such a DDIM Inversion and BLIP), this method can also be used to copy the style of a reference image (similarly to other style transfer techniques):

Underlying principles 🔗
As said above, this method is “optimization-free”, meaning that it does not require any additional training or fine-tuning, which can be computationnaly expensive. It will simply modify/patch the architecture of the Stable Diffusion model. Particularly, it will add a Shared-Attention mechanism to each Self-Attention block of the U-Net, which will allow the generated images to “attend” to the first image of the batch, and thus copy its style. This is illustrated in Figure 3 of the paper:

This Shared-Attention mechanism is illustrated in the paper in Figure 4 and can be described as follows:
- The target images’ keys (Kt) and queries (Qt) are normalized using AdaIN against the reference image respective keys (Kr) and queries (Qr). This gives us the normalized target keys (K̂t) and queries (Q̂t).
- The reference image values (Vr) and keys (Kr) are then concatenated to the target images’ respective values (Vt) and keys (K̂t).
- The resulting queries, keys and values are then used to compute an attention map, where the target images will be able “attend” to the reference image, and copy its style.

Official implementation 🔗
Google has graciously blessed us with an official implementation of this method, which can be found in their GitHub repository. This implementation uses the 🤗 Diffusers library, and can be found in the sa_handler.py file.
Diffusers exposes an AttnProcessor class which allows developpers to override the behaviour of the Attention layers. The official Style Aligned implementation thus overrides the forward method of each Attention layers of a Stable Diffusion U-Net model with the following:
def shared_call(
self,
attn: attention_processor.Attention,
hidden_states,
encoder_hidden_states = None,
attention_mask = None,
**kwargs
):
# define some useful variables from the inputs
residual = hidden_states
input_ndim = hidden_states.ndim
if input_ndim == 4:
batch_size, channel, height, width = hidden_states.shape
hidden_states = hidden_states.view(batch_size, channel, height * width).transpose(1, 2)
batch_size, sequence_length, _ = hidden_states.shape if encoder_hidden_states is None else encoder_hidden_states.shape
# apply an attention mask, if provided
if attention_mask is not None:
attention_mask = attn.prepare_attention_mask(attention_mask, sequence_length, batch_size)
# scaled_dot_product_attention expects attention_mask shape to be (batch, heads, source_length, target_length)
attention_mask = attention_mask.view(batch_size, attn.heads, -1, attention_mask.shape[-1])
# apply a GroupNorm to hidden_states, if configured to do so
if attn.group_norm is not None:
hidden_states = attn.group_norm(hidden_states.transpose(1, 2)).transpose(1, 2)
# get queries, keys and values from hidden_states
query = attn.to_q(hidden_states)
key = attn.to_k(hidden_states)
value = attn.to_v(hidden_states)
inner_dim = key.shape[-1]
head_dim = inner_dim // attn.heads
# reshape queries, keys and values to (batch, heads, sequence_length, head_dim)
query = query.view(batch_size, -1, attn.heads, head_dim).transpose(1, 2)
key = key.view(batch_size, -1, attn.heads, head_dim).transpose(1, 2)
value = value.view(batch_size, -1, attn.heads, head_dim).transpose(1, 2)
# apply AdaIN to queries, keys and values, if configured to do so
if self.adain_queries:
query = adain(query)
if self.adain_keys:
key = adain(key)
if self.adain_values:
value = adain(value)
# apply shared attention, if configured to do so
if self.share_attention:
key = concat_first(key, -2, scale=self.shared_score_scale)
value = concat_first(value, -2)
if self.shared_score_shift != 0:
hidden_states = self.shifted_scaled_dot_product_attention(attn, query, key, value)
else:
hidden_states = nnf.scaled_dot_product_attention(query, key, value, attn_mask=attention_mask, dropout_p=0.0, is_causal=False)
else:
hidden_states = nnf.scaled_dot_product_attention(query, key, value, attn_mask=attention_mask, dropout_p=0.0, is_causal=False)
# reshape hidden_states to (batch, sequence_length, heads * head_dim)
hidden_states = hidden_states.transpose(1, 2).reshape(batch_size, -1, attn.heads * head_dim)
hidden_states = hidden_states.to(query.dtype)
# apply output projection to hidden_states
hidden_states = attn.to_out[0](hidden_states)
# apply output dropout to hidden_states
hidden_states = attn.to_out[1](hidden_states)
# reshape hidden_state to (batch, channel, height, width), if necessary
if input_ndim == 4:
hidden_states = hidden_states.transpose(-1, -2).reshape(batch_size, channel, height, width)
# apply residual connection, if configured to do so
if attn.residual_connection:
hidden_states = hidden_states + residual
# rescale hidden_states by the output factor
hidden_states = hidden_states / attn.rescale_output_factor
return hidden_states
The code above is essentially a copy-paste of the original code of the default AttnProcessor, with the Shared-Attention mechanism added in the middle. Patching the layer in this manner is straightforward and easy to do, but it comes with the drawbacks of being:
- Difficult to maintain
- Hard to make interoperable with other additional methods
Refiners implementation 🔗
Let’s now take a look at how we can implement this method in Refiners. First of all, let’s zoom out a little from Figure 4 and vizualize an entire Self-Attention block:
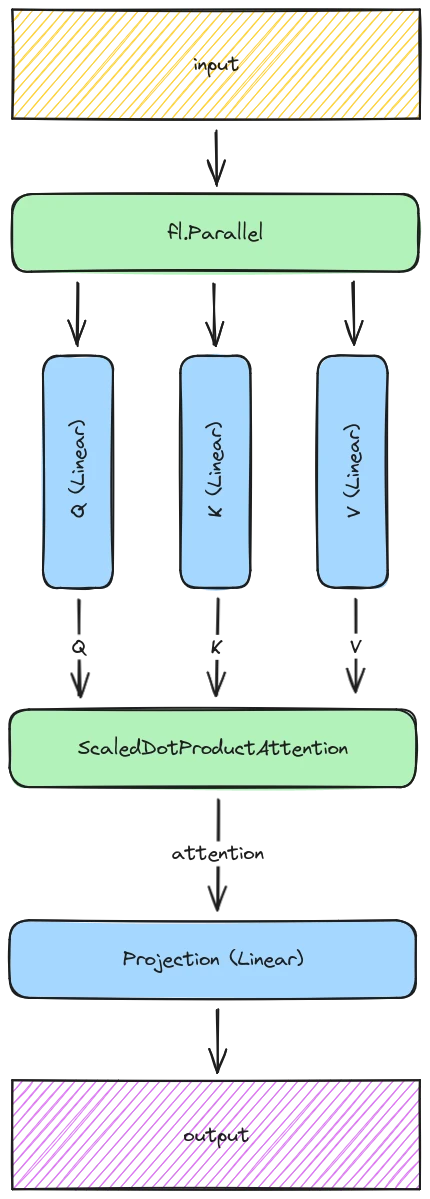
From what we have gathered in the Underlying principles section, we can infer that implementing the Shared-Attention mechanism in Refiners sums up to inserting some small (stateless) StyleAligned layers right before the ScaledDotProductAttention layer, like so:
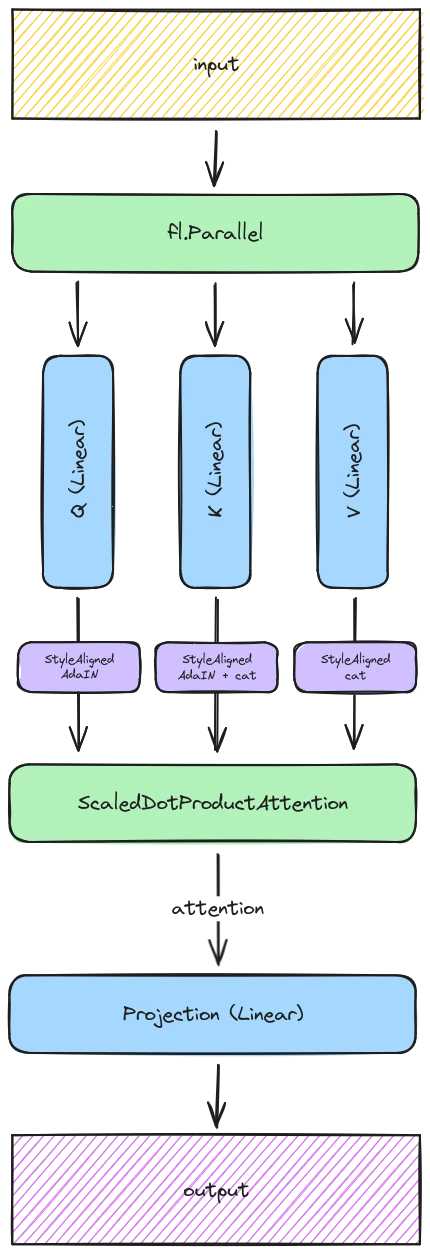
The StyleAligned layers simply chain a couple operations, reproducing the behavior of the original implementation made by Google. Visually, it looks like this:
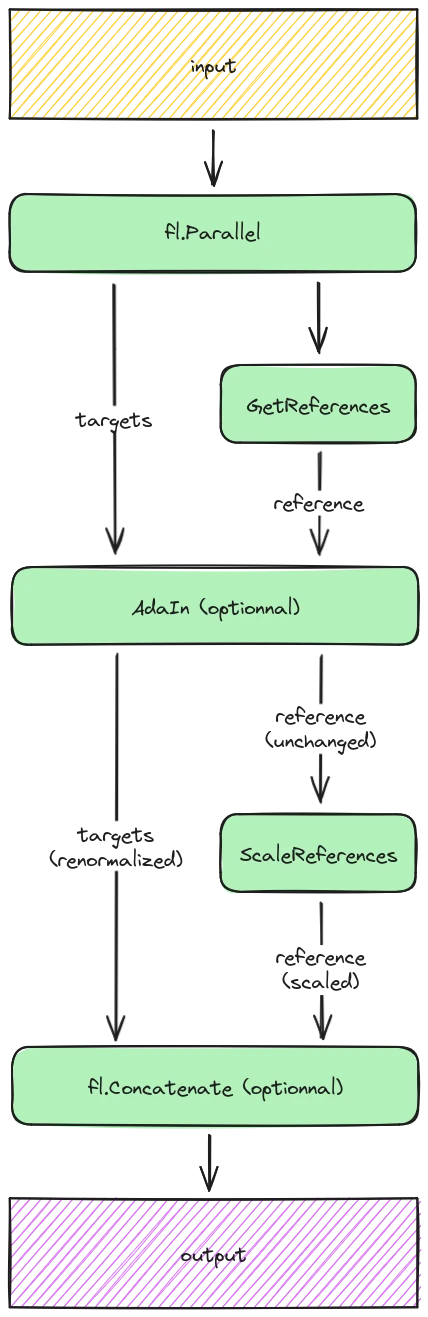
The GetReferences, AdaIn, and ScaleReferences layers all respectively correspond to expand_first, adain and shared_score_scale of the official implementation.
Finally we can neatly wrap all this in an Adapter called StyleAlignedAdapter that can easily be injected into a StableDiffusion_XL model, like so:
sdxl = StableDiffusion_XL()
style_aligned_adapter = StyleAlignedAdapter(sdxl.unet)
style_aligned_adapter.inject()
Here is the result of the Refiners implementation when using the same parameters as seen in the Introduction section:

Laurent from the Finegrain Team